
ในตอนที่แล้ว เราได้ตื่นตาตื่นใจกับความสามารถของ AI ในฐานะคู่คิดอัจฉริยะในห้องปฏิบัติการยุทธการและการคำนวณส่งกำลังบำรุงสาย พธ. และ อร. ไปแล้ว ซึ่งแน่นอนว่าระบบเจ๋งๆ เหล่านั้นจะรันอยู่บนโครงสร้าง Cloud 3.0 ระบบปิดที่เราภาคภูมิใจ แต่เคยมีใครสงสัยไหมครับว่า “ก่อนที่ AI ตัวนี้จะเก่งจนตอบคำถามและพยากรณ์สิ่งต่างๆ ได้… มันต้องผ่านอะไรมาบ้าง?”
เปรียบเหมือนเรือรบหลวงลำหนึ่งครับ กว่าจะปล่อยลงน้ำและออกปฏิบัติภารกิจได้อย่างสง่างาม ก็ต้องเริ่มจากการออกแบบ การคัดเลือกเหล็กกล้า และการเชื่อมประกอบในอู่ต่อเรืออย่างประณีต วันนี้ผมจะพาทุกท่านไปทัวร์หลังบ้าน ดูพิมพ์เขียวและขั้นตอนการสร้างสมองกลของพวกเราใน ตอนที่ 6: เบื้องหลังการสร้าง “RTN AI”: การเตรียมข้อมูลและการฝึกฝนระบบ ครับ!
🛠️ จากกองขยะกระดาษ สู่เหล็กกล้าชั้นดี
หากเรามองย้อนกลับไปในอดีต ยุคที่คำสั่ง ระเบียบ และบันทึกประวัติศาสตร์ของกองทัพเรือถูกพิมพ์ด้วยพิมพ์ดีดหรือเขียนด้วยลายมือ แฟ้มเอกสารสีน้ำตาลถูกมัดรวมกันและจัดเก็บไว้ในห้องคลังเอกสารที่เต็มไปด้วยฝุ่น ปัญหาคือเอกสารบางส่วนสูญหาย ปลวกกิน หรือข้อความเลือนลางตามกาลเวลา ข้อมูลเหล่านั้นเปรียบเหมือน “แร่เหล็กดิบที่ฝังอยู่ใต้ดิน” ที่ยังไม่ได้ผ่านการถลุง จึงไม่สามารถนำมาใช้ประโยชน์อะไรได้เต็มที่
แต่ในปัจจุบัน ยุคดิจิทัลได้เปลี่ยนให้แร่เหล็กเหล่านั้นกลายเป็น “น้ำมันดิบแห่งศตวรรษที่ 21” (Data is the new oil) แต่อย่าลืมนะครับว่า น้ำมันดิบจะไม่มีค่าเลยถ้าไม่ผ่านการกลั่น เช่นเดียวกับระบบ AI ครับ ต่อให้เราซื้อซอฟต์แวร์ราคาเป็นร้อยล้านมาติดตั้งบน Cloud 3.0 แต่ถ้าข้อมูลที่เราป้อนให้มันอ่านเป็นข้อมูลที่มั่ว ขยะ หรือไม่เป็นระเบียบ AI ก็จะตอบกลับมาเป็นขยะเช่นกัน
ในทางทหาร มีคำกล่าวสั้นๆ ที่คุ้นเคยในสายการส่งกำลังบำรุงและการเตรียมความพร้อม:
“Garbage in, garbage out.” (GIGO) (ใส่ขยะเข้าไป ข้อมูลที่ได้ออกมาก็คือขยะ)
แต่ในมิติการสร้าง AI ความมั่นคงระดับบิ๊กดาต้า เรามี Motto ที่ลึกซึ้งกว่านั้นคือ:
“Data Readiness is Operational Readiness.” (ความพร้อมด้านข้อมูล คือความพร้อมรบเชิงยุทธการ)
เพราะสมองกลจะฉลาดหรืออัจฉริยะได้ ไม่ได้ขึ้นอยู่กับว่าระบบแพงแค่ไหน แต่มันขึ้นอยู่กับ “คุณภาพของข้อมูล” ที่กำลังพลทุกคนร่วมกันสร้างและจัดเก็บต่างหากครับ
⚙️ เจาะลึกกระบวนการทำงาน: 3 ขั้นตอนถลุงข้อมูลดิบสู่ “RTN AI”
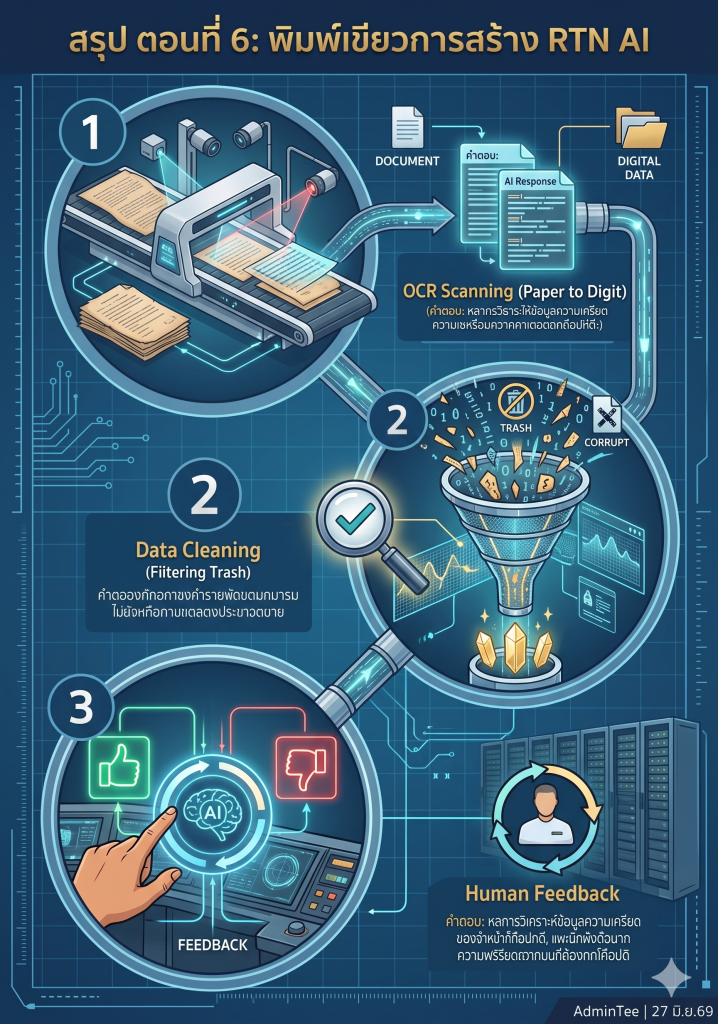
กว่าจะเกิดเป็น “RTN AI” (Royal Thai Navy AI) สมองกลที่เก่งกาจ มีกระบวนการวิศวกรรมข้อมูลเบื้องหลัง 3 ขั้นตอนหลักๆ ที่น่าสนใจดังนี้ครับ:
[1. Digitalization (สแกน/แปลงไฟล์)] ➡️ [2. Data Cleaning & Indexing (ทำความสะอาด/จัดดัชนี)] ➡️ [3. Feedback Loop (กำลังพลร่วมประเมิน)]

1. Digitalization (ข้อมูลที่ดีมีค่ามากกว่าระบบที่แพง): ขั้นตอนแรกคือการเปลี่ยนโครงสร้างจากกระดาษสู่ดิจิทัล แต่มันไม่ใช่แค่การสแกนเอกสารเป็นไฟล์ PDF ภาพถ่ายแล้วจบนะครับ เพราะ AI อ่านข้อความจากรูปภาพตรงๆ ไม่ได้ กระบวนการนี้ต้องใช้เทคโนโลยี OCR (Optical Character Recognition) เพื่อสกัดตัวอักษรภาษาไทยและภาษาอังกฤษออกมาเป็นข้อความดิจิทัลที่ค้นหาได้ (Searchable Text) นี่คือรากฐานที่สำคัญที่สุด

2. Data Cleaning & Indexing (การทำความสะอาดข้อมูลและการทำดัชนี): ข้อมูลทหารเรือบางครั้งมีหน้าว่าง เอกสารซ้ำซ้อน หรือข้อความที่พิมพ์ผิด ทีมงานวิศวกรข้อมูล (Data Engineer) จะต้องทำ Data Cleaning เพื่อตัดขยะเหล่านี้ออก จากนั้นจะเข้าสู่ขั้นตอนการทำ Vector Indexing หรือการจัดทำดัชนีเชิงความหมาย โดยระบบจะแบ่งเอกสารยาวๆ ออกเป็นท่อนๆ (Chunking) แล้วฝังรหัสคณิตศาสตร์ไว้ เพื่อให้เวลาทำงานจริง ระบบ RAG สามารถพุ่งไปหยิบข้อความท่อนที่ถูกต้องมาให้ AI ตอบได้อย่างรวดเร็วใน 3 วินาที
3. Human-in-the-Loop & Feedback Loop (บทบาทสำคัญของกำลังพล ทร.): นี่คือจุดที่สำคัญที่สุดครับ AI ไม่ได้เรียนรู้เสร็จในครั้งเดียว แต่มันจะฉลาดขึ้นทุกวันผ่าน Feedback Loop โดยกำลังพลผู้ใช้งานจริงจะทำหน้าที่เป็น “ครูฝึก” เมื่อ AI ตอบคำถาม กำลังพลสามารถกดปุ่ม 👍 (คำตอบถูกต้อง/มีประโยชน์) หรือ 👎 (คำตอบคลาดเคลื่อน/ผิดระเบียบ) การประเมินเหล่านี้จะถูกส่งกลับไปให้โมเดลประมวลผลเพื่อปรับจูน (Fine-tuning) ตัวเอง ทำให้มันเข้าใจบริบททหารเรือไทยได้แม่นยำยิ่งขึ้นเรื่อยๆ
🏢 องค์กรต้นแบบความสำเร็จ
องค์กรยักษ์ใหญ่ระดับโลกอย่าง NASA (องค์การบริหารการบินและอวกาศแห่งชาติ) ได้ประสบความสำเร็จอย่างมากในการสร้าง AI เฉพาะทางเพื่อช่วยวิเคราะห์พิมพ์เขียวและรายงานความล้มเหลวของภารกิจในอดีต (Lessons Learned) เบื้องหลังความสำเร็จไม่ได้เกิดจากโปรแกรมเมอร์เพียงไม่กี่คน แต่เกิดจากการที่วิศวกรและเจ้าหน้าที่ทุกคนร่วมมือกันทำ Digitalization และเคลียร์ข้อมูลรายงานเก่าๆ ตลอด 50 ปีให้อยู่ในรูปแบบที่สะอาด (Clean Data) ส่งผลให้ AI ของ NASA สามารถช่วยค้นหาวิธีแก้ไขปัญหายานอวกาศขัดข้องได้อย่างแม่นยำและกลายเป็นคลังสมองกลที่มีมูลค่ามหาศาล
📝 บทสรุปประจำตอน
เบื้องหลังความอัจฉริยะของ “RTN AI” ไม่ใช่เวทมนตร์ แต่คือหยาดเหงื่อและวินัยในการจัดการข้อมูลขององค์กร การสร้าง AI เฉพาะทางเพื่อความมั่นคงจึงไม่ใช่หน้าที่ นขต.ทร. หน่วยใดหน่วยหนึ่ง แต่เป็นบทบาทของ กำลังพลกองทัพเรือทุกนาย ในการจัดเก็บเอกสารอย่างเป็นระบบ เลิกพิมพ์คำผิด และช่วยกันกดโหวตประเมินคำตอบ เพื่อร่วมกันหล่อหลอมให้สมองกลของ ทร. ลำนี้ แข็งแกร่งและพร้อมรบทางปัญญาอย่างแท้จริงครับ!
📚 เอกสารอ้างอิง
- NASA Knowledge Management Office. (2024). Data Cleaning and Digitalization Practices for Aerospace Mission Success.
- Joint Artificial Intelligence Center (JAIC). (2025). DoD Data Strategy: Transforming Data for AI Readiness.
🔗 Link อ้างอิง
- ยุทธศาสตร์การจัดการข้อมูลเพื่อเตรียมความพร้อมสู่ AI ของ DoD
- ถอดบทเรียนการทำ Data Governance จาก NASA
💬 คำถามเพื่อการมีส่วนร่วม
- ปัจจุบันในหน่วยงานของท่าน เอกสารส่วนใหญ่ยังเป็นระบบกระดาษ หรือเปลี่ยนเป็นไฟล์ดิจิทัล (Word/PDF) แล้วกี่เปอร์เซ็นต์?
- ท่านเคยเจอปัญหา “พิมพ์ค้นหาไฟล์งานในคอมพิวเตอร์ตัวเองไม่เจอ” หรือไม่? คิดว่าระบบการจัดดัชนี (Indexing) ของ AI จะเข้ามาช่วยท่านได้อย่างไร?
- ในฐานะผู้ใช้งาน ท่านพร้อมที่จะเป็น “ครูฝึก” คอยกดให้คะแนน (Feedback) เพื่อให้ AI ของ ทร. ฉลาดขึ้นในทุกๆ วันหรือไม่?
⚓ เชิญชวนติดตามตอนต่อไป:
และแล้วเราก็เดินทางมาถึงตอนสุดท้ายของซีรีส์นี้ ! ห้ามพลาดกับบทสรุปครั้งสำคัญในหัวข้อ “ตอนที่ 7: ก้าวสู่อนาคต: กองทัพเรือยุคขับเคลื่อนด้วยปัญญาประดิษฐ์ (AI-Driven Navy)” เราจะมาวาดพิมพ์เขียวร่วมกันว่า เมื่อเทคโนโลยีทั้งหมดเชื่อมต่อกัน ทร. ของเราจะยืดหยัดอย่างสง่างามในโลกอนาคตได้อย่างไร… เจอกันตอนหน้าครับ!
Talk is cheap. Show me the code.