
หัวข้อ: Data Governance in AI Era: เตรียมข้อมูลให้พร้อม ก่อนคิดใช้ AI (ตอนที่ 8)
จากบทความในตอนที่ผ่านมา เราได้กล่าวถึงความสำคัญของการคุ้มครองข้อมูลส่วนบุคคล (PDPA) ไปแล้ว ในลำดับถัดมา เมื่อองค์กรเริ่มนำเทคนิค Retrieval-Augmented Generation (RAG) มาประยุกต์ใช้เพื่อสร้างระบบคลังความรู้อัจฉริยะ ประเด็นความท้าทายใหม่ที่เกิดขึ้นคือ “การควบคุมการเข้าถึงข้อมูล” (Access Control) ซึ่งหากขาดการกำกับดูแลที่รัดกุม อาจนำไปสู่การรั่วไหลของข้อมูลภายในที่มีชั้นความลับ
ส่วนที่ 3: ธรรมาภิบาลและความปลอดภัย (Security, Privacy & Ethics)
ตอนที่ 8: Access Control for RAG: ใครมีสิทธิ์เห็นอะไร?
การนำเทคโนโลยี RAG มาใช้ คือการเชื่อมต่อ Generative AI เข้ากับฐานข้อมูลขององค์กร เพื่อให้ AI สามารถตอบคำถามเฉพาะทางได้ อย่างไรก็ตาม กระบวนการนี้มาพร้อมกับความเสี่ยงด้านความปลอดภัยข้อมูล ดังนี้:

1. ปัญหาช่องโหว่ของการสืบค้น (The Vulnerability of Unfiltered Retrieval)
- โดยปกติ ระบบฐานข้อมูลแบบเดิมจะมีระบบจัดการสิทธิ์ (File Permission) แต่เมื่อข้อมูลถูกแปลงเป็น Vector และนำไปเก็บใน Vector Database เพื่อให้ AI ใช้งาน สิทธิ์เหล่านั้นมัก “ตกหล่น” ไป
- ผลกระทบ: AI จะมีสถานะเป็น Super User ที่มองเห็นเอกสารทุกฉบับ เมื่อผู้ใช้งาน (เช่น พนักงานทั่วไป) สอบถามข้อมูลที่มีความอ่อนไหว (เช่น เงินเดือนผู้บริหาร, สัญญาความลับทางยุทธศาสตร์) AI จะดึงข้อมูลเหล่านั้นมาสรุปเป็นคำตอบให้อย่างถูกต้องและครบถ้วน ซึ่งถือเป็นการรั่วไหลของข้อมูล (Internal Data Leakage)
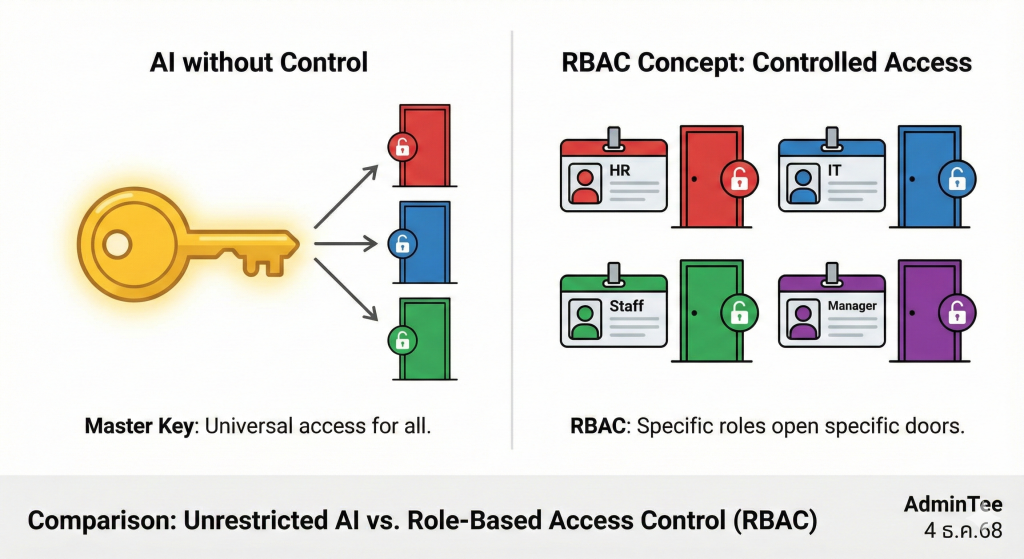
2. การวางโครงสร้างสิทธิ์ (Access Control Frameworks)
- เพื่อป้องกันปัญหาข้างต้น องค์กรจำเป็นต้องบูรณาการระบบสิทธิ์เข้ากับ Pipeline ของ AI:
- Role-Based Access Control (RBAC): การกำหนดสิทธิ์ตาม “บทบาทหน้าที่” ข้อมูลจะถูกดึงมาใช้ได้ก็ต่อเมื่อผู้ถามมีบทบาทที่เกี่ยวข้อง เช่น ข้อมูลด้านงบประมาณจะถูกดึงมาประมวลผลให้เฉพาะเจ้าหน้าที่การเงินเท่านั้น
- Attribute-Based Access Control (ABAC): การกำหนดสิทธิ์ตาม “คุณลักษณะ” ที่ละเอียดขึ้น เช่น ระดับชั้นความลับของเอกสาร (Confidential Level), เวลาที่เข้าถึง, หรือสถานที่เข้าถึง
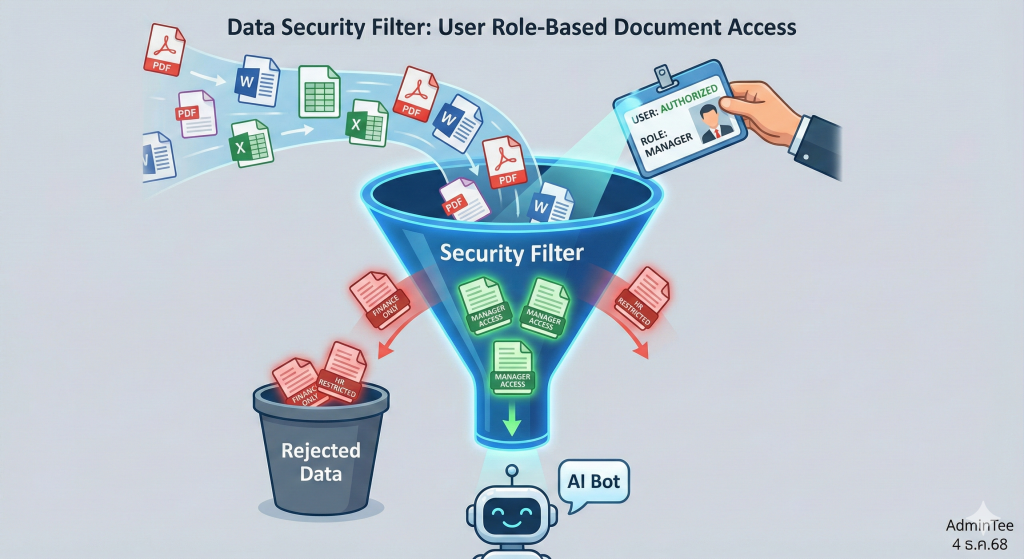
3. ธรรมาภิบาลความปลอดภัยข้อมูล (Data Security Governance)
- แนวทางปฏิบัติที่ดี (Best Practice) คือการใช้เทคนิค “Pre-retrieval Filtering” กล่าวคือ ระบบต้องตรวจสอบสิทธิ์ของผู้ใช้งาน ก่อน ที่จะส่งคำสั่งไปค้นหาข้อมูลในฐานข้อมูล
- หากผู้ใช้งานไม่มีสิทธิ์ในเอกสารใด เอกสารนั้นจะต้องถูก “กรองออก” จากผลการค้นหาทันที เสมือนว่าเอกสารนั้นไม่มีอยู่จริง (Invisible) ก่อนที่ข้อมูลจะถูกส่งต่อไปให้ AI ทำการสรุปผล
บทสรุป
ความสะดวกสบายในการเข้าถึงข้อมูล ต้องมาพร้อมกับความปลอดภัย การทำ Data Governance ในยุค AI ไม่ใช่เพียงการจัดการคุณภาพข้อมูล แต่ต้องครอบคลุมถึงการออกแบบสถาปัตยกรรมความปลอดภัย (Security Architecture) ที่สามารถจำกัดสิทธิ์การรับรู้ข้อมูลของ AI ให้สอดคล้องกับสิทธิ์ของมนุษย์ผู้ใช้งานอย่างเคร่งครัด
คำถามเพื่อการมีส่วนร่วม (Engagement Questions)
- ท่านมีความกังวลหรือไม่ หากนำ AI Chatbot มาใช้ค้นหาเอกสารภายใน แล้ว AI จะนำข้อมูลลับมาเปิดเผย?
- ปัจจุบันการกำหนดสิทธิ์เข้าถึงไฟล์ในหน่วยงานของท่าน ใช้วิธีการใดเป็นหลัก (กำหนดรายบุคคล หรือ กำหนดตามกลุ่มงาน)?
- หาก AI ปฏิเสธการตอบคำถามเนื่องจากติดสิทธิ์การเข้าถึง ท่านคิดว่า AI ควรแจ้งเหตุผลให้ผู้ใช้ทราบหรือไม่?
ลิงก์ที่เกี่ยวข้อง (Related Links)
- OWASP: Top 10 for Large Language Model Applications (LLM06: Sensitive Information Disclosure)
- Gartner: Design Pattern for RAG Security
ติดตามตอนต่อไป
ในตอนหน้า (ตอนที่ 9) เราจะเข้าสู่ประเด็น “AI Ethics & Explainability” เมื่อ AI เริ่มมีบทบาทในการช่วยตัดสินใจ เราจะมั่นใจได้อย่างไรว่าการตัดสินใจนั้นเป็นธรรมและสามารถอธิบายเหตุผลเบื้องหลังได้? ติดตามได้ในสัปดาห์หน้าครับ
Hashtags: #AdminTee #OncBlog #NavyITBlog #InformationSecurity #RAGSecurity #ZeroTrust #DigitalGovernment
บทแทรก
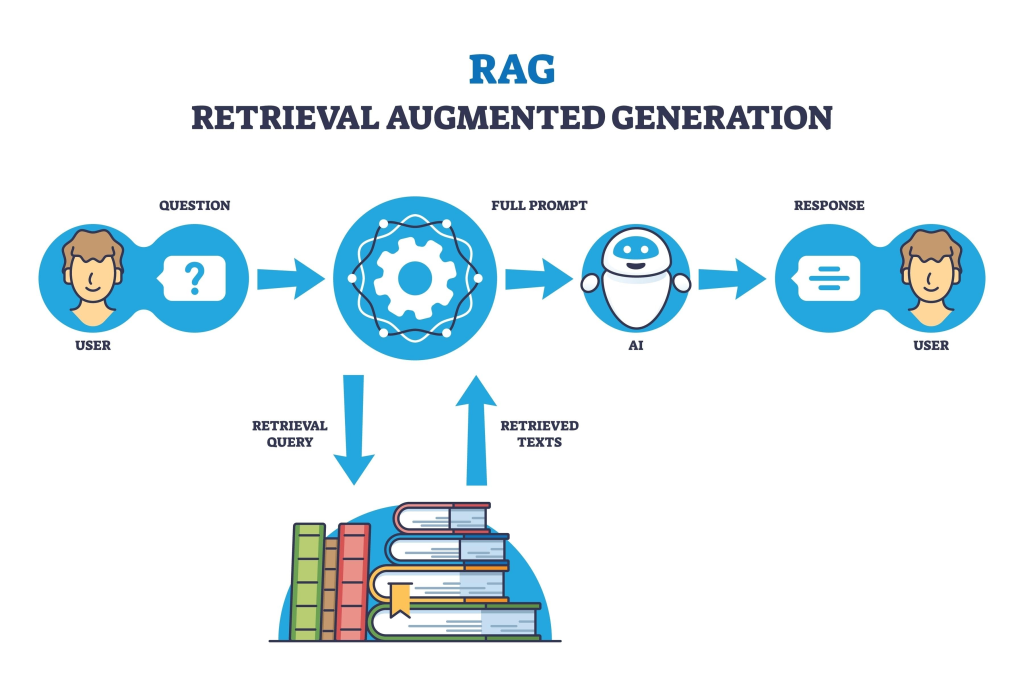
Retrieval-Augmented Generation (RAG) คือเทคนิคที่ช่วยให้ AI (เช่น ChatGPT, Gemini) ฉลาดขึ้นและตอบคำถามได้แม่นยำขึ้น โดยการ “อนุญาตให้ AI เปิดหนังสือสอบ”
ปกติ AI จะตอบคำถามจากความรู้ที่มันถูกฝึกมา (Training Data) ซึ่งอาจจะเก่าหรือไม่ครบถ้วน แต่ RAG จะเพิ่มขั้นตอนการ “ไปค้นหาข้อมูล (Retrieve)” จากฐานข้อมูลภายนอก (เช่น เอกสารบริษัท, เว็บไซต์ล่าสุด) แล้วนำข้อมูลที่เจอมาประกอบการ “สร้างคำตอบ (Generate)” ให้ผู้ใช้งาน
กระบวนการทำงาน:
- รับคำถาม: ผู้ใช้ถามคำถาม
- ค้นหา: ระบบนำคำถามไปค้นหาข้อมูลที่เกี่ยวข้องในฐานข้อมูล (Vector Database)
- ส่งต่อ: นำข้อมูลที่ค้นเจอ + คำถาม ส่งให้ AI
- ตอบ: AI ประมวลผลและสรุปคำตอบจากข้อมูลที่ได้รับ
Case Study ที่ใช้จริงในปัจจุบัน ปัจจุบัน RAG เป็นหัวใจสำคัญของระบบ AI ในระดับ Enterprise
- Microsoft 365 Copilot:
- นี่คือตัวอย่าง RAG ที่ชัดเจนที่สุด เมื่อเราถาม Copilot ใน Word หรือ Teams มันไม่ได้ใช้แค่ความรู้ทั่วไป แต่ใช้ RAG ไปค้นหาข้อมูลในอีเมล, ไฟล์ OneDrive, และปฏิทินของคุณ เพื่อมาตอบคำถามเฉพาะตัวของคุณ
- Customer Support Bot (ธุรกิจธนาคาร/ประกันภัย):
- แทนที่จะให้ AI ตอบกว้างๆ แชทบอทสมัยใหม่จะใช้ RAG เชื่อมต่อกับ “คู่มือกรมธรรม์” หรือ “เงื่อนไขโปรโมชั่นล่าสุด” เมื่อลูกค้าถาม ระบบจะดึงเงื่อนไขที่ถูกต้องเป๊ะๆ มาตอบ ลดปัญหาการตอบผิด (Hallucination)
- Legal Research Assistant (ผู้ช่วยทนายความ):
- สำนักงานกฎหมายใช้ RAG เพื่อสืบค้นคลังคำพิพากษาย้อนหลังนับหมื่นคดี AI จะดึงคดีที่ใกล้เคียงที่สุดขึ้นมาสรุปให้ทนายความนำไปร่างสำนวนต่อ
ข้อดี และ ข้อเสีย
| ข้อดี | ข้อเสีย |
| 1. ข้อมูลสดใหม่เสมอ: ไม่ต้องรอเทรนโมเดลใหม่ แค่อัปเดตไฟล์ในฐานข้อมูล AI ก็รู้เรื่องทันที | 1. ความซับซ้อนสูง: ต้องมีการจัดการ Vector Database และดูแลคุณภาพข้อมูล (Data Governance) ที่ดี |
| 2. ลดอาการ “หลอน” (Hallucination): เพราะ AI ถูกบังคับให้ตอบตามข้อมูลอ้างอิงที่มีอยู่จริง (Grounding) | 2. ความล่าช้า (Latency): กระบวนการ “ค้นหา” ก่อน “ตอบ” อาจทำให้ตอบช้ากว่าการถาม AI ตรงๆ เล็กน้อย |
| 3. รักษาความลับข้อมูล (Privacy): ข้อมูลองค์กรไม่ต้องถูกส่งไปเทรนให้ผู้ให้บริการ AI (Model Provider) ข้อมูลยังอยู่กับเรา | 3. คุณภาพขึ้นอยู่กับการค้นหา: ถ้าค้นหาข้อมูลมาผิด (Retrieval Fail) AI ก็จะตอบผิด (Garbage In, Garbage Out) |
| 4. ประหยัดค่าใช้จ่าย: ถูกกว่าการนำ AI ไป Fine-tuning (สอนเพิ่ม) มาก |
ปัจจุบัน RAG ถูกทดแทนด้วยเทคโนโลยีใด?
จริงๆ แล้ว RAG ยังไม่ตาย และยังเป็นมาตรฐานหลักอยู่ แต่กำลังเผชิญหน้ากับคู่แข่งและวิวัฒนาการใหม่ๆ ดังนี้:
- 1. Long Context Window (การรองรับข้อมูลยาวพิเศษ)
- คืออะไร: โมเดลรุ่นใหม่ๆ อย่าง Gemini 1.5 Pro หรือ GPT-4o สามารถรับข้อมูลได้ระดับ 1-2 ล้าน Tokens (เทียบเท่าหนังสือหลายสิบเล่ม) ในครั้งเดียว
- มาแทน RAG ได้ไหม?: ในบางกรณี ถ้าข้อมูลเราไม่เยอะมาก เราสามารถ “โยนไฟล์ทั้งหมด” เข้าไปใน Prompt ได้เลยโดยไม่ต้องทำระบบ RAG หรือฐานข้อมูลค้นหาให้ยุ่งยาก AI อ่านทั้งหมดแล้วตอบได้เลย แม่นยำกว่าด้วย
- 2. GraphRAG (Knowledge Graph RAG)
- คืออะไร: เป็นร่างพัฒนาของ RAG ปกติ RAG ทั่วไปค้นหาคำที่ “คล้ายกัน” (Vector Similarity) แต่ GraphRAG ใช้ “กราฟความรู้” เชื่อมโยงความสัมพันธ์ของข้อมูล
- ดีกว่ายังไง: ช่วยให้ AI เข้าใจความสัมพันธ์ที่ซับซ้อนได้ เช่น “นาย A เป็นลูกน้องนาย B และนาย B ดูแลโปรเจกต์ C” ซึ่ง RAG ธรรมดาอาจหาความเชื่อมโยงนี้ไม่เจอ
- 3. Fine-tuning (เฉพาะงาน)
- คืออะไร: การนำโมเดลมาสอนซ้ำด้วยข้อมูลเฉพาะทาง
- มาแทน RAG ได้ไหม?: ใช้แทนในกรณีที่ต้องการปรับ “สไตล์การตอบ” หรือ “ศัพท์เทคนิคเฉพาะทาง” แต่ถ้าต้องการความแม่นยำของข้อมูล Fact ปัจจุบัน RAG ยังคงเป็นทางเลือกที่ดีที่สุด
รวมตอบคำถามชิงรางวัล เมื่อจบ Serries (ตอนที่ 15 มอบรางวัล)
https://docs.google.com/forms/d/e/1FAIpQLSfkDcgYIkX5KW1KKHgiFj29q4rB3IFZS6Xaup-yIwGPK8KGkw/viewform?usp=preview

Talk is cheap. Show me the code.