
หลังจากที่เราทราบถึงที่มาและข้อกฎหมายกันไปแล้ว คำถามต่อมาคือ “เราจะจัดระเบียบข้อมูลมหาศาลของกองทัพเรือได้อย่างไร?” ในระบบ CKAN มีการวางโครงสร้างที่เป็นสากลแต่ยืดหยุ่นพอที่จะปรับให้เข้ากับสายงานของทหารเรือได้ วันนี้ AdminTee จะพาทุกท่านไปดูหัวใจสำคัญของการจัดหมวดหมู่ข้อมูล เพื่อให้การค้นหาข้อมูลในกองทัพเป็นเรื่องที่ง่ายและรวดเร็วเหมือนการเปิดสมุดโทรศัพท์ครับ
เนื้อหาหลัก
1. จุดประสงค์

- เพื่อให้เจ้าหน้าที่ระบบและกำลังพลเข้าใจโครงสร้างหลักของ CKAN (Organizations, Datasets, Resources)
- เพื่อวางรากฐานการจัดกลุ่มข้อมูล (Data Taxonomy) ให้สอดคล้องกับโครงสร้างสายงานของกองทัพเรือ
- เพื่อสร้างมาตรฐานในการจัดเก็บข้อมูลที่ทุกหน่วยงานสามารถใช้ร่วมกันได้อย่างเป็นระบบ
2. ความต้องการ
- การกำหนด “หน่วยงานเจ้าของข้อมูล” (Organizations) ที่ชัดเจนตาม นขต.ทร.
- การจัดหมวดหมู่ชุดข้อมูล (Datasets) ที่ครอบคลุมทุกมิติภารกิจ
- การเตรียมไฟล์ข้อมูล (Resources) ให้หลากหลายรูปแบบเพื่อให้ระบบต่างๆ นำไปใช้งานต่อได้
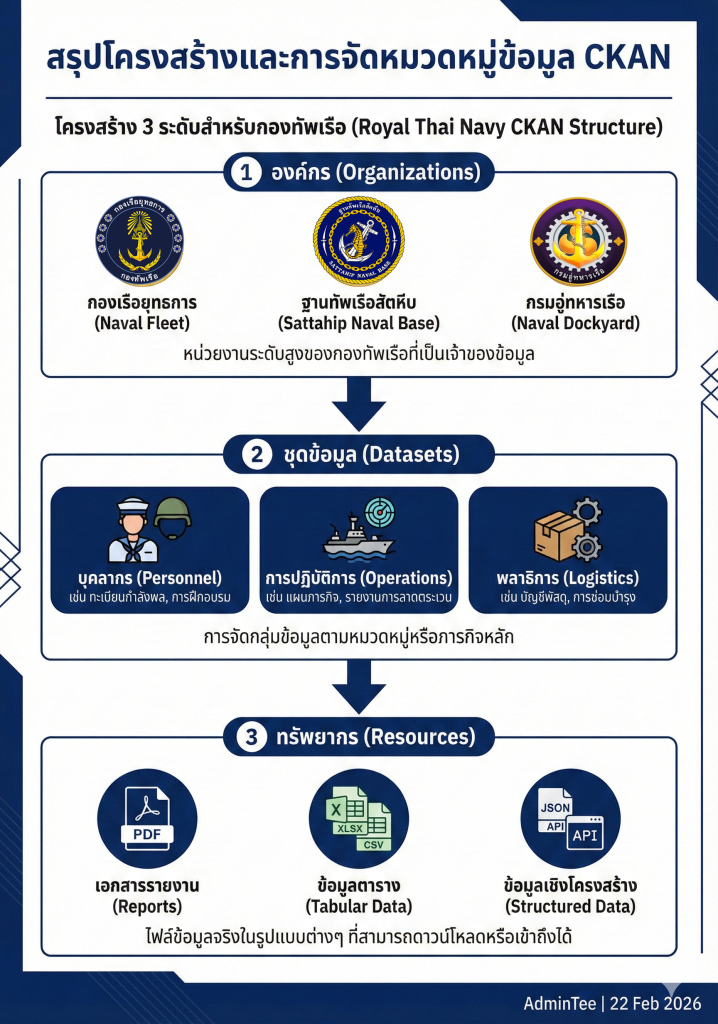
3. ลงรายละเอียดส่วนประกอบของ CKAN

- Organizations (องค์กร): คือหน่วยงานที่รับผิดชอบข้อมูล เช่น กรมกำลังพลทหารเรือ (กพ.ทร.) หรือ กรมส่งกำลังบำรุงทหารเรือ (กบ.ทร.) ซึ่งแต่ละองค์กรจะมีผู้ดูแลคอยจัดการข้อมูลของตนเอง
- Datasets (ชุดข้อมูล): คือกลุ่มของข้อมูลที่มีเรื่องราวเดียวกัน เช่น “สถิติรายชื่อพิพิธภัณฑ์ทหารเรือ” โดยในหนึ่งชุดข้อมูลจะประกอบด้วยคำอธิบาย (Metadata) ว่าข้อมูลนี้เกี่ยวกับอะไร ใครเป็นคนทำ
- Resources (ทรัพยากรข้อมูล): คือตัวไฟล์ข้อมูลจริงๆ ที่อยู่ในชุดข้อมูลนั้นๆ เช่น ไฟล์ Excel (.csv), ไฟล์เอกสาร (.pdf) หรือ ลิงก์เชื่อมโยงไปยังระบบอื่น (API)
4. ยกตัวอย่างการดำเนินการ (การออกแบบ Data Taxonomy ตามสายงาน ทร.)

- สายกำลังพล: จัดกลุ่มข้อมูลเกี่ยวกับ สถิติกำลังพลแยกตามชั้นยศ, บัญชีรายชื่อหน่วยงานใน ทร. เพื่อความสะดวกในการติดต่อประสานงาน
- สายยุทธการ: จัดกลุ่มข้อมูลเกี่ยวกับ พิกัดตำแหน่งที่ตั้งหน่วยงานทหารเรือ, แผนที่เดินเรือเบื้องต้นสำหรับประชาชน
- สายส่งกำลังบำรุง: จัดกลุ่มข้อมูลเกี่ยวกับ รายการพัสดุสายชูชีพ, ข้อมูลราคากลางพัสดุที่เปิดเผยได้ เพื่อเป็นฐานข้อมูลในการจัดซื้อจัดจ้าง
สรุปเนื้อหาพอสังเขป
การจัดโครงสร้าง CKAN ที่ดีต้องเริ่มจากการเข้าใจบทบาทของ Organizations และการแบ่ง Datasets ให้ชัดเจน หากเราออกแบบการจัดกลุ่มข้อมูล (Taxonomy) ได้สอดคล้องกับสายงาน ทร. จะช่วยให้การบูรณาการข้อมูลระหว่างหน่วยงานทำได้อย่างไร้รอยต่อ และลดความซ้ำซ้อนของข้อมูลได้ครับ
ติดตามในตอนต่อไป
ในตอนที่ 4 AdminTee จะพาไปดูขั้นตอนการทำงานจริง “Data Ingestion” หรือวิธีการนำข้อมูลเข้าสู่ระบบอย่างถูกวิธี ต้องเตรียมไฟล์อย่างไรและเขียน Metadata แบบไหนให้ค้นหาเจอได้ง่าย ห้ามพลาดนะครับ!
ลิงก์เอกสารอ้างอิง
- คู่มือการจัดกลุ่มหมวดหมู่ข้อมูลภาครัฐ (Data Taxonomy Guide)
ลิงก์เว็บไซต์ที่เกี่ยวข้อง
คำถามเพื่อการมีส่วนร่วม
- ท่านคิดว่าโครงสร้างหน่วยงาน (Organizations) ในระบบ CKAN ควรแบ่งตาม นขต.ทร. หรือแบ่งตามภารกิจหลัก?
- ข้อมูลในสายงานของท่าน ชุดใดที่ควรจัดกลุ่มเป็น “ชุดข้อมูลยอดนิยม” (Top Datasets) ที่มีการใช้งานบ่อยที่สุด?
- หากต้องตั้งชื่อหมวดหมู่ข้อมูล (Taxonomy) ให้เข้าใจง่ายสำหรับกำลังพลทั่วไป ท่านมีข้อเสนอแนะอย่างไร?
Talk is cheap. Show me the code.