
สืบเนื่องจากบทความตอนที่ผ่านมา ซึ่งได้กล่าวถึงเกณฑ์คุณภาพข้อมูลเชิงปริมาณและสถิติ (4V) ไปแล้ว ในตอนที่ 6 นี้ AdminTee จะพาทุกท่านก้าวข้ามขีดจำกัดของการจัดการข้อมูลแบบดั้งเดิม เข้าสู่การบริหารจัดการ “ข้อมูลมืด” (Dark Data) และ “ข้อมูลไร้โครงสร้าง” (Unstructured Data) ซึ่งถือเป็นทรัพยากรหลัก (Fuel) ในการขับเคลื่อน Generative AI ในปัจจุบัน
ส่วนที่ 2: เสาหลักคุณภาพข้อมูล (The Data Foundation)
ตอนที่ 6: จัดการ “Dark Data” และ Unstructured Data
ข้อมูลภายในองค์กรกว่าร้อยละ 80 จัดอยู่ในรูปแบบ Unstructured Data เช่น เอกสาร PDF, อีเมล, ไฟล์เสียง, และรูปภาพ ซึ่งในอดีตมักถูกมองข้าม (Dark Data) เนื่องจากข้อจำกัดในการนำไปประมวลผล แต่ในยุค AI Data Governance เราจำเป็นต้องมีกลยุทธ์การจัดการที่ชัดเจน ดังนี้

1. ความท้าทายของข้อมูลไร้โครงสร้างกับ Gen AI
- แม้นวัตกรรม Generative AI (LLMs) จะมีความสามารถในการทำความเข้าใจภาษาและรูปภาพได้ดี แต่การนำข้อมูลดิบเหล่านี้เข้าสู่ระบบโดยปราศจากการคัดกรอง อาจนำมาซึ่งความเสี่ยง 2 ประการ:
- Noise & Hallucination: ข้อมูลที่ไม่เกี่ยวข้อง (Noise) ในเอกสาร อาจทำให้ AI สับสนและประมวลผลผิดพลาด
- Privacy Risks: ข้อมูลส่วนบุคคล (PII) ที่ซ่อนอยู่ในเอกสารสแกน ยากต่อการตรวจสอบและปกปิด (Redact) ด้วยเครื่องมือแบบเดิม

2. มาตรฐานการทำ Labeling และ Annotation
- เพื่อให้ AI เรียนรู้ได้อย่างแม่นยำ (Supervised Learning) จำเป็นต้องมีกระบวนการ “ระบุฉลากข้อมูล” (Data Labeling)
- ธรรมาภิบาลในขั้นตอนนี้คือ: การกำหนดมาตรฐาน (Annotation Guidelines) ที่ชัดเจน เพื่อลดความไม่แน่นอน (Ambiguity) ของผู้ปฏิบัติงาน เช่น การกำหนดขอบเขตของการวงกลมวัตถุในภาพ (Bounding Box) หรือการระบุประเภทของเจตนา (Intent Classification) ในข้อความ ให้เป็นไปในทิศทางเดียวกันทั้งองค์กร
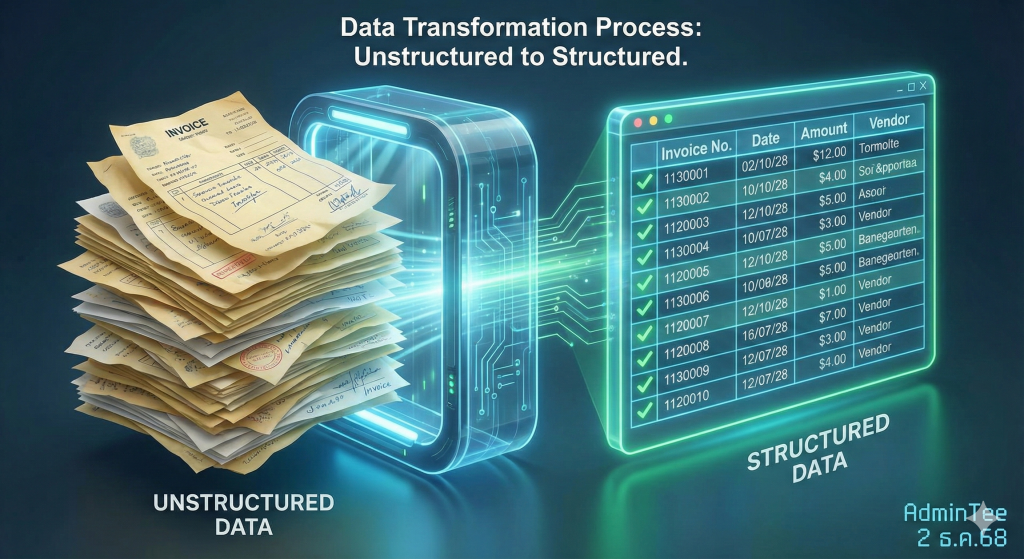
3. การแปลง Unstructured ให้เป็น Structured เพื่อการตรวจสอบ (Auditability)
- การตรวจสอบความถูกต้องของข้อมูล (Data Validation) บนไฟล์ PDF หรือรูปภาพ ทำได้ยากและใช้เวลานาน
- แนวทางปฏิบัติ: ควรใช้เทคโนโลยี เช่น OCR (Optical Character Recognition) หรือ NLP (Natural Language Processing) เพื่อสกัดข้อมูลสำคัญ (Key-Value Pairs) ออกมาให้อยู่ในรูปแบบตาราง (Structured Format) ก่อน
- ประโยชน์: ช่วยให้สามารถใช้ Rule-based Logic ในการตรวจสอบความสมเหตุสมผลของข้อมูล (เช่น ตรวจสอบยอดรวมในใบเสร็จ) ได้โดยอัตโนมัติ ก่อนนำไปใช้เทรน AI
บทสรุป
การเปลี่ยน “Dark Data” ให้เป็น “Smart Data” ไม่ใช่เพียงการจัดซื้อเครื่องมือ AI แต่คือการวางกระบวนการ (Process) ตั้งแต่การค้นหา การทำ Labeling ที่มีมาตรฐาน ไปจนถึงการแปลงสภาพข้อมูลเพื่อการตรวจสอบ หากปราศจากการกำกับดูแลในส่วนนี้ AI ที่ได้มาอาจเป็นเพียง “กล่องดำ” ที่เราไม่สามารถวางใจในผลลัพธ์ได้
ปรดติดตามตอนต่อไป: ในตอนที่ 7 เราจะเจาะลึกประเด็นข้อกฎหมายและจริยธรรม ในหัวข้อ “PDPA/GDPR กับ AI: เส้นแบ่งบางๆ ที่ห้ามก้าวข้าม”
Hashtags: #AdminTee #OncBlog #NavyITBlog #DataGovernance #DarkDataManagement #AILabelling #DigitalTransformation
รวมตอบคำถามชิงรางวัล เมื่อจบ Serries (ตอนที่ 15 มอบรางวัล)
https://docs.google.com/forms/d/1bKBSUU_ZIA6uj0tQxEfvSer1TiiH7_di3ImZE_U6UM0/preview

Talk is cheap. Show me the code.